From Tedious Labor to Automated Workflows
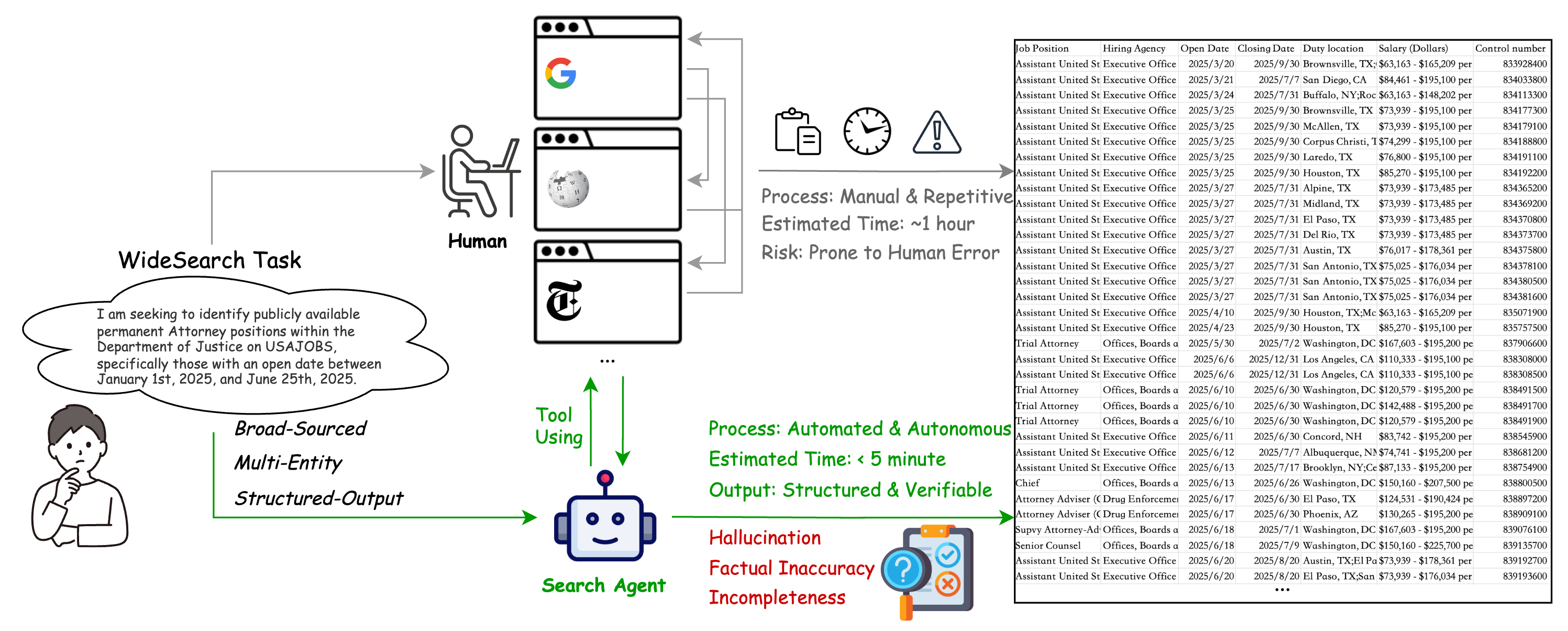
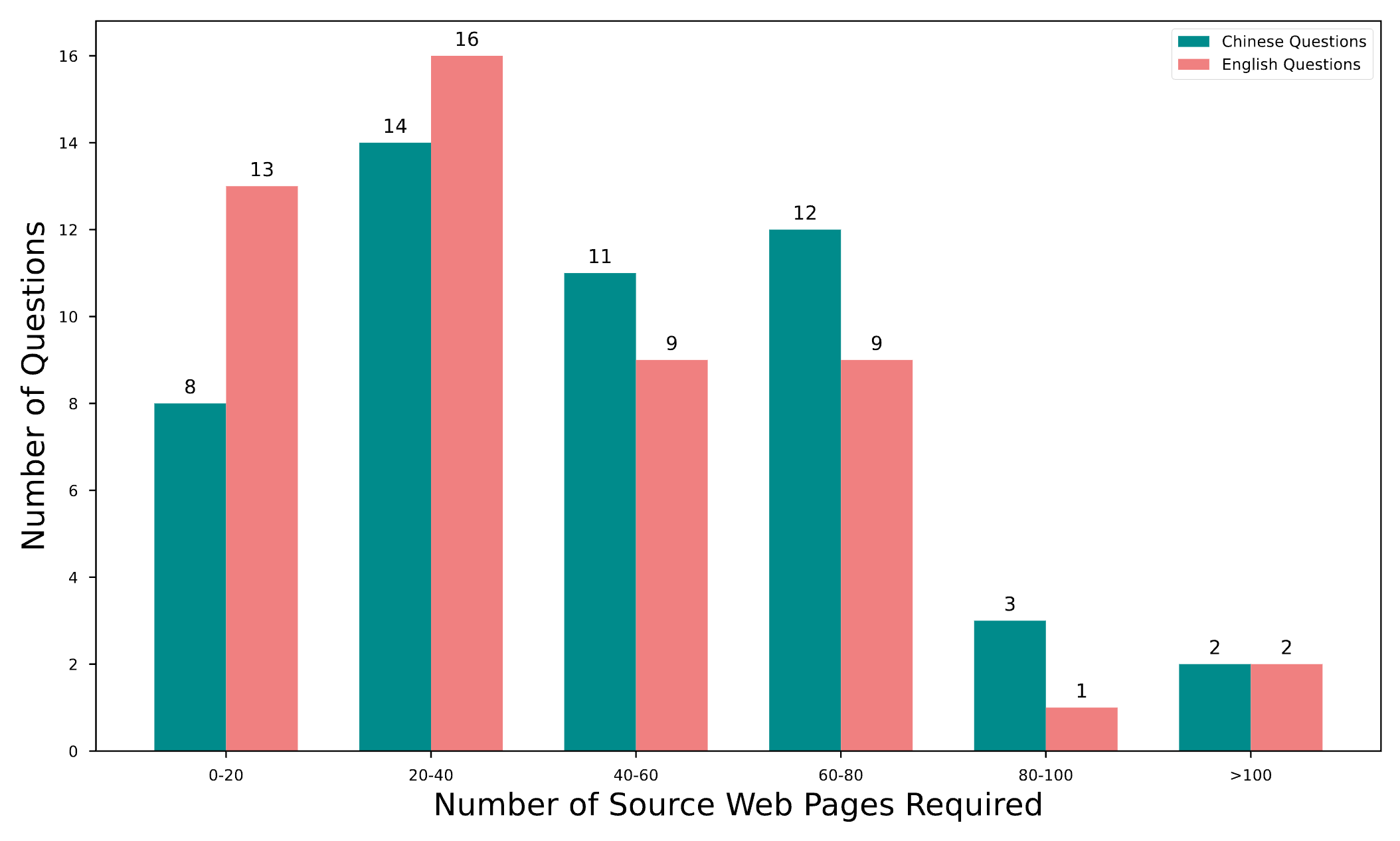
Many real-world information-gathering tasks are not hard, just huge. Consider a financial analyst compiling key metrics for all companies in a sector, or a job seeker collecting every vacancy that meets their criteria. The challenge isn't cognitive complexity, but the sheer scale and repetitive nature of the work—a critical productivity bottleneck.
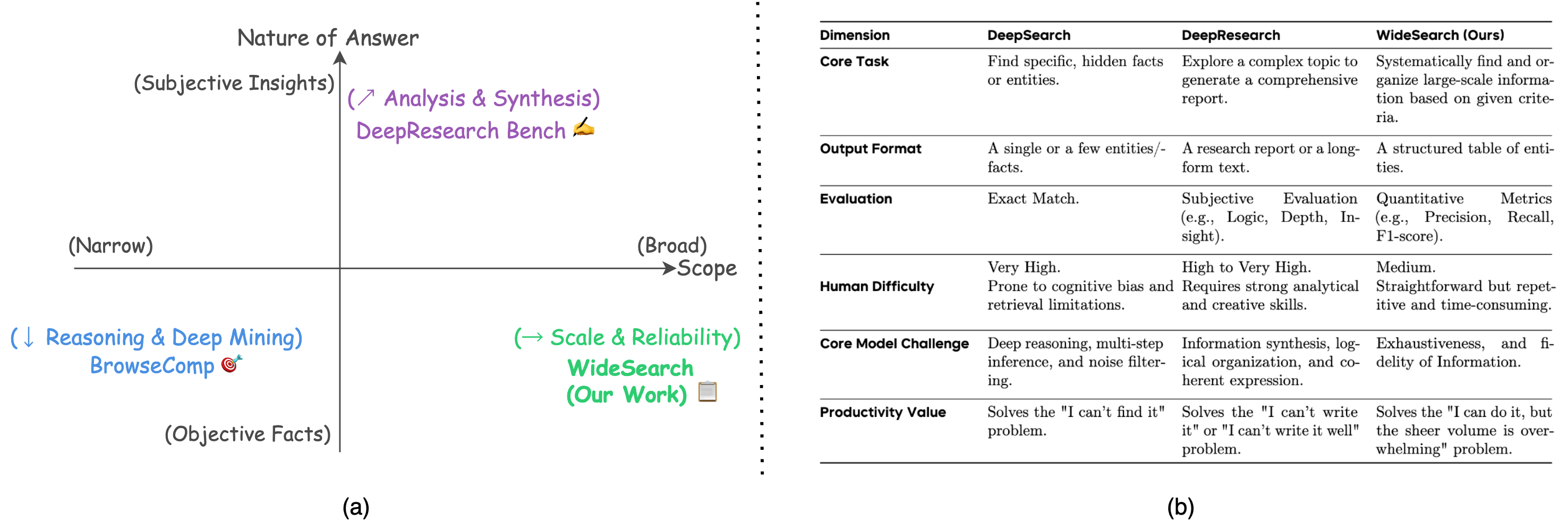
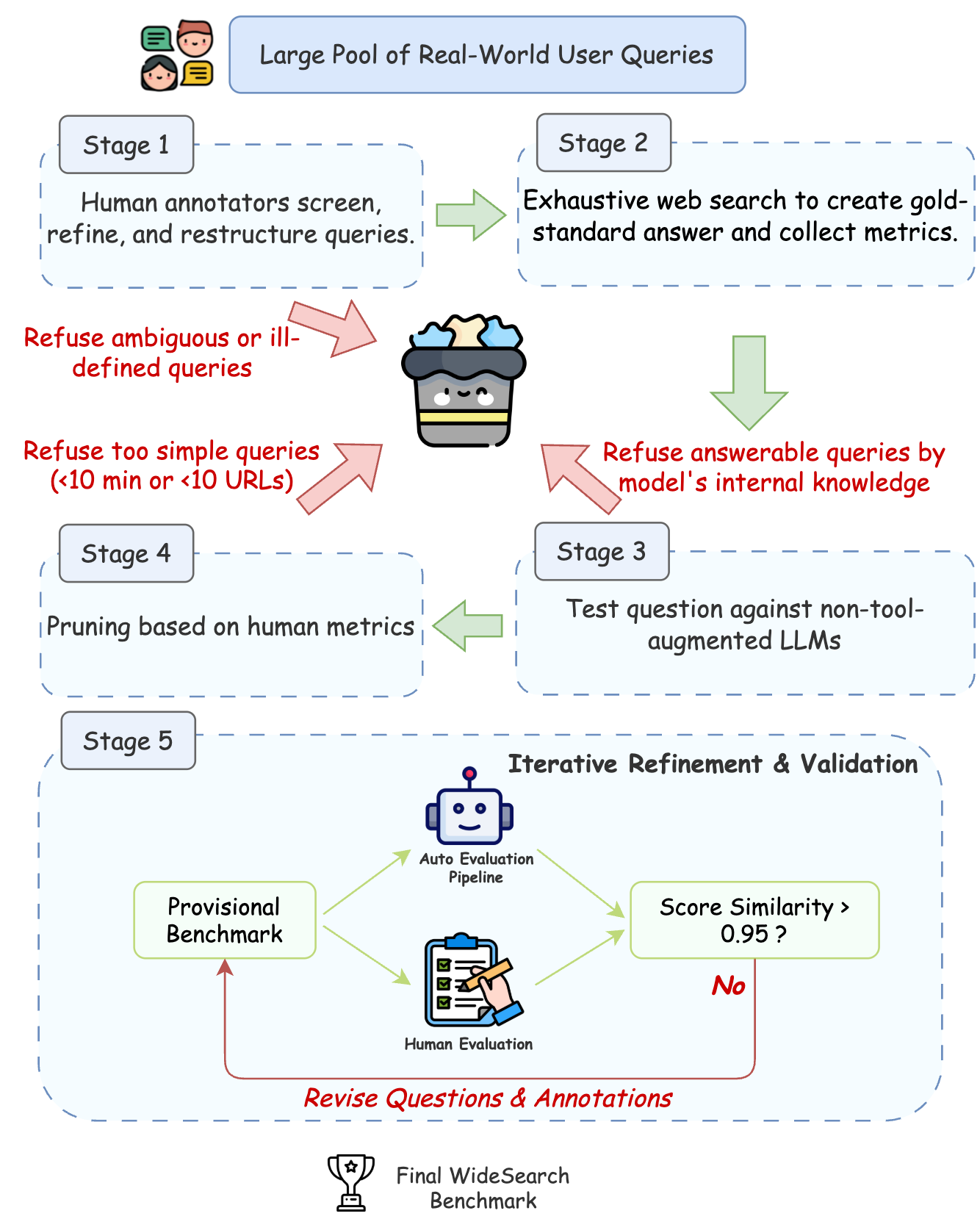
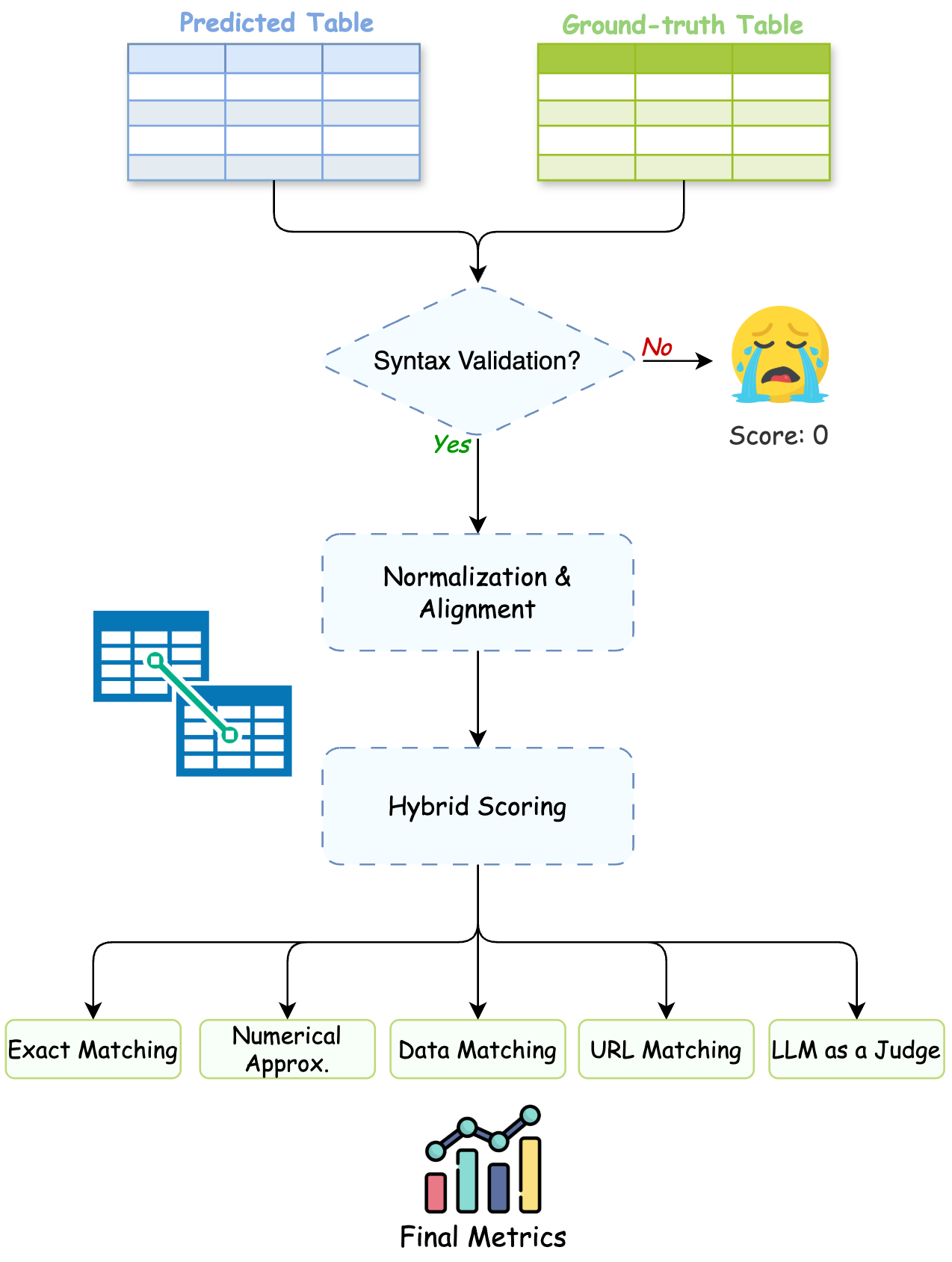
WideSearch is designed to evaluate an agent's ability to automate these tasks, shifting from laborious manual collection to efficient, automated workflows. This shift, however, introduces novel failure modes like hallucination and incompleteness, making rigorous evaluation essential.